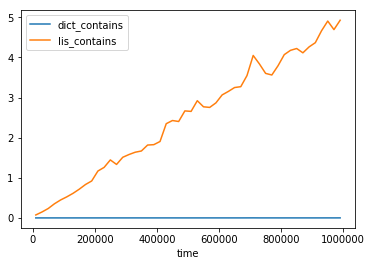
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| pop(0) pop()
0.56428, 0.00026
1.46132, 0.00009
2.27953, 0.00007
3.11111, 0.00025
4.03941, 0.00007
5.01496, 0.00011
5.72766, 0.00008
6.41760, 0.00007
6.98101, 0.00016
7.69488, 0.00009
8.59127, 0.00008
9.39142, 0.00008
10.03456, 0.00007
10.85724, 0.00011
11.69828, 0.00008
12.37023, 0.00008
13.12709, 0.00010
13.89727, 0.00008
14.65594, 0.00007
15.49640, 0.00008
16.35027, 0.00008
17.00838, 0.00010
17.72517, 0.00008
19.29465, 0.00010
21.02476, 0.00008
21.60967, 0.00008
22.32767, 0.00008
22.62550, 0.00008
25.15527, 0.00009
24.14118, 0.00008
25.48768, 0.00009
24.84720, 0.00007
26.40644, 0.00008
26.62662, 0.00008
28.86800, 0.00008
27.79692, 0.00008
|